4 Le microprocesseur
Un microprocesseur est un circuit intégré complexe caractérisé par une très grande intégration et doté des facultés d'interprétation et d'exécution des instructions d'un programme.
Il est chargé d’organiser les tâches précisées par le programme et d’assurer leur exécution.
Il est chargé d’organiser les tâches précisées par le programme et d’assurer leur exécution.
Il doit aussi prendre en compte les informations extérieures au système et assurer leur traitement. C’est le cerveau du système.
A l’heure actuelle, un microprocesseur regroupe sur quelques millimètre carré des fonctionnalités toujours plus complexes. Leur puissance continue de s’accroître et leur encombrement diminue régulièrement respectant toujours, pour le moment, la fameuse loi de Moore (1).
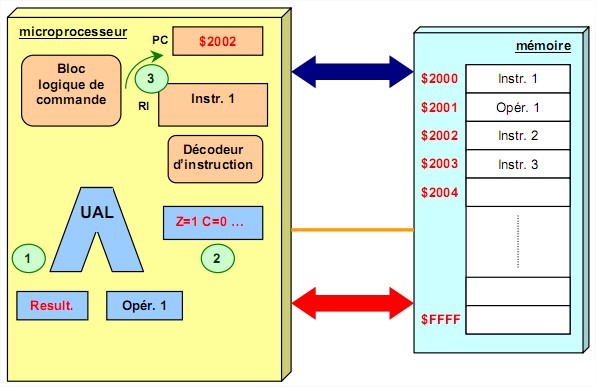
4.1 Architecture de base d’un microprocesseur A l’heure actuelle, un microprocesseur regroupe sur quelques millimètre carré des fonctionnalités toujours plus complexes. Leur puissance continue de s’accroître et leur encombrement diminue régulièrement respectant toujours, pour le moment, la fameuse loi de Moore (1).
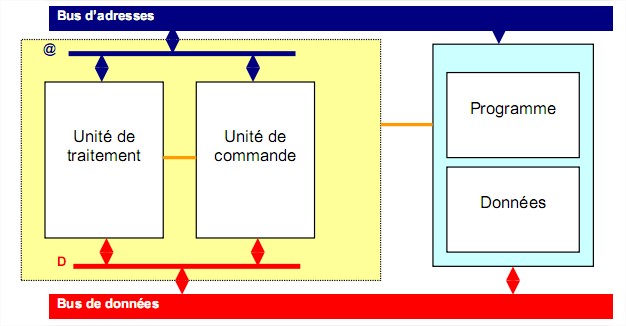
Un microprocesseur est construit autour de deux éléments principaux :
 Une unité de commande Une unité de traitement
Une unité de commande Une unité de traitementassociés à des registres chargées de stocker les différentes informations à traiter. Ces trois éléments sont reliés entre eux par des bus interne permettant les échanges d’informations.
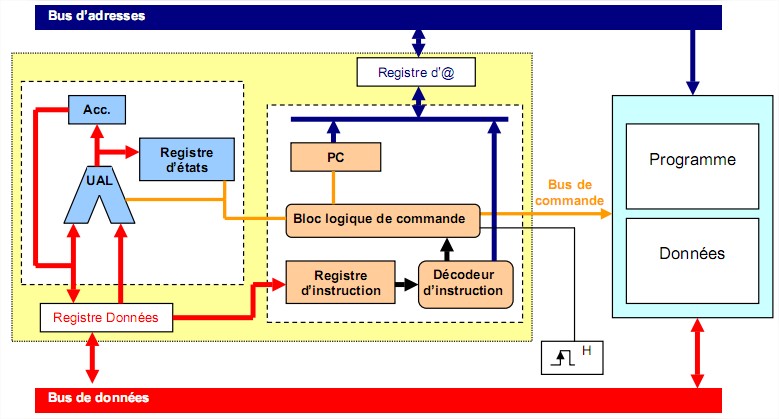
Il existe deux types de registres :
les registres d'usage général permettent à l'unité de traitement de manipuler des données à vitesse élevée. Ils sont connectés au bus données interne au microprocesseur. les registres d'adresses (pointeurs) connectés sur le bus adresses.4.1.1 L’unité de commande
Elle permet de séquencer le déroulement des instructions. Elle effectue la recherche en mémoire de l'instruction. Comme chaque instruction est codée sous forme binaire, elle en assure le décodage pour enfin réaliser son exécution puis effectue la préparation de l'instruction suivante. Pour cela, elle est composée par :
le compteur de programme constitué par un registre dont le contenu est initialisé avec l'adresse de la première instruction du programme. Il contient toujours l’adresse de l’instruction à exécuter. (1) Moore (un des co-fondateurs de la société Intel) a émis l'hypothèse que les capacités technologiques permettraient de multiplier par 2 tous les 18 mois le nombre de transistors intégrés sur les circuits.
Le registre d'instruction et le décodeur d'instruction : chacune des instructions à exécuter est rangée dans le registre instruction puis est décodée par le décodeur d’instruction. Bloc logique de commande (ou séquenceur) : Il organise l'exécution des instructions au rythme d’une horloge. Il élabore tous les signaux de synchronisation internes ou externes (bus de commande) du microprocesseur en fonction des divers signaux de commande provenant du décodeur d’instruction ou du registre d’état par exemple. Il s'agit d'un automate réalisé soit de façon câblée (obsolète), soit de façon micro-programmée, on parle alors de microprocesseur.4.1.2 L’unité de traitement
C’est le cœur du microprocesseur. Elle regroupe les circuits qui assurent les traitements nécessaires à l'exécution des instructions :
L’Unité Arithmétique et Logique (UAL) est un circuit complexe qui assure les fonctions logiques (ET, OU, Comparaison, Décalage , etc…) ou arithmétique (Addition, soustraction). Le registre d'état est généralement composé de 8 bits à considérer individuellement. Chacun de ces bits est un indicateur dont l'état dépend du résultat de la dernière opération effectuée par l’UAL. On les appelle indicateur d’état ou flag ou drapeaux. Dans un programme le résultat du test de leur état conditionne souvent le déroulement de la suite du programme. On peut citer par exemple les indicateurs de :
 retenue (carry : C) retenue intermédiaire (Auxiliary-Carry : AC) signe (Sign : S) débordement (overflow : OV ou V) zéro (Z) parité (Parity : P) Les accumulateurs sont des registres de travail qui servent à stocker une opérande au début d'une opération arithmétique et le résultat à la fin de l'opération.
retenue (carry : C) retenue intermédiaire (Auxiliary-Carry : AC) signe (Sign : S) débordement (overflow : OV ou V) zéro (Z) parité (Parity : P) Les accumulateurs sont des registres de travail qui servent à stocker une opérande au début d'une opération arithmétique et le résultat à la fin de l'opération. 4.1.3 Schéma fonctionnel
4.2 Cycle d’exécution d’une instruction
Le microprocesseur ne comprend qu’un certain nombre d’instructions qui sont codées en binaire. Le traitement d’une instruction peut être décomposé en trois phases.
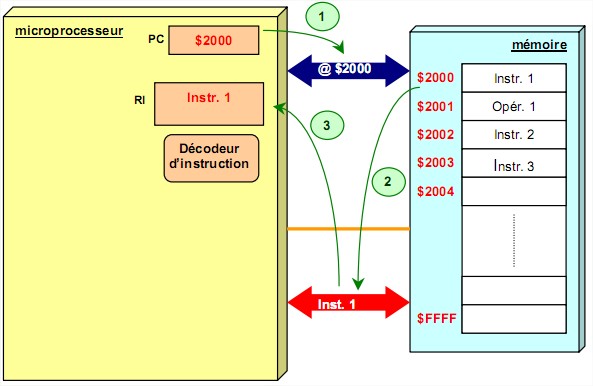
Phase 1: Recherche de l'instruction à traiter 1. Le PC contient l'adresse de l'instruction suivante du programme. Cette valeur est placée sur le bus d'adresses par l'unité de commande qui émet un ordre de lecture.
2. Au bout d'un certain temps (temps d'accès à la mémoire), le contenu de la case mémoire sélectionnée est disponible sur le bus des données.
3. L'instruction est stockée dans le registre instruction du processeur.
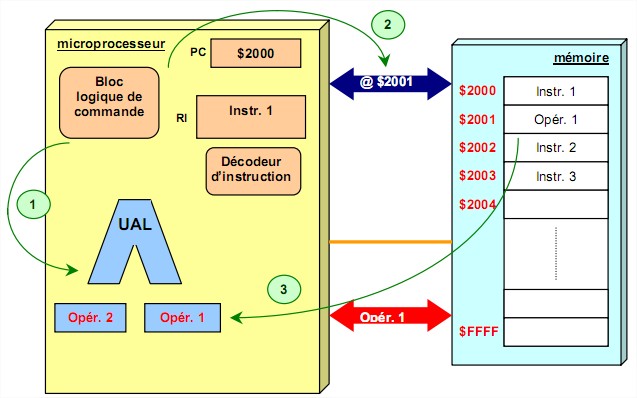
 Phase 2 : Décodage de l’instruction et recherche de l'opérande
Phase 2 : Décodage de l’instruction et recherche de l'opérandeLe registre d'instruction contient maintenant le premier mot de l'instruction qui peut être codée sur
plusieurs mots. Ce premier mot contient le code opératoire qui définit la nature de l'opération à effectuer (addition, rotation,...) et le nombre de mots de l'instruction.
1. L'unité de commande transforme l'instruction en une suite de commandes élémentaires nécessaires au traitement de l'instruction.
2. Si l'instruction nécessite une donnée en provenance de la mémoire, l'unité de commande récupère sa valeur sur le bus de données.
3. L’opérande est stockée dans un registre.
 Phase 3 : Exécution de l'instruction
Phase 3 : Exécution de l'instruction 1. Le micro-programme réalisant l'instruction est exécuté.
2. Les drapeaux sont positionnés (registre d'état).
3. L'unité de commande positionne le PC pour l'instruction suivante.
4.3 Jeu d’instructions
4.3.1 Définition
La première étape de la conception d’un microprocesseur est la définition de son jeu
d’instructions. Le jeu d’instructions décrit l’ensemble des opérations élémentaires que le
microprocesseur pourra exécuter. Il va donc en partie déterminer l’architecture du microprocesseur à réaliser et notamment celle du séquenceur. A un même jeu d’instructions peut correspondre un grand nombre d’implémentations différentes du microprocesseur.
4.3.2 Type d’instructions
Les instructions que l’on retrouve dans chaque microprocesseur peuvent être classées en 4 groupes :
Transfert de données pour charger ou sauver en mémoire, effectuer des transferts de registre à registre, etc… Opérations arithmétiques : addition, soustraction, division, multiplication Opérations logiques : ET, OU, NON, NAND, comparaison, test, etc… Contrôle de séquence : branchement, test, etc… 4.3.3 Codage
Les instructions et leurs opérandes (paramètres) sont stockés en mémoire principale. La taille
totale d’une instruction (nombre de bits nécessaires pour la représenter en mémoire) dépend du type d’instruction et aussi du type d’opérande. Chaque instruction est toujours codée sur un nombre entier d’octets afin de faciliter son décodage par le processeur. Une instruction est composée de deux champs :
le code instruction, qui indique au processeur quelle instruction réaliser le champ opérande qui contient la donnée, ou la référence à une donnée en mémoire (son adresse). Exemple :

Ainsi un octet permet de distinguer au maximum 256 instructions différentes.
4.3.4 Mode d’adressage
Un mode d'adressage définit la manière dont le microprocesseur va accéder à l’opérande.
Les différents modes d'adressage dépendent des microprocesseurs mais on retrouve en général :
l'adressage de registre où l’on traite la données contenue dans un registre l'adressage immédiat où l’on définit immédiatement la valeur de la donnée l'adressage direct où l’on traite une données en mémoire Selon le mode d’adressage de la donnée, une instruction sera codée par 1 ou plusieurs octets.
4.3.5 Temps d’exécution
Chaque instruction nécessite un certain nombre de cycles d’horloges pour s’effectuer.
Le nombre de cycles dépend de la complexité de l’instruction et aussi du mode d’adressage.
Il est plus long d’accéder à la mémoire principale qu’à un registre du processeur.
La durée d’un cycle dépend de la fréquence d’horloge du séquenceur.
 4.4 Langage de programmation
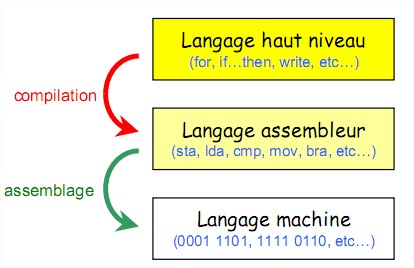
4.4 Langage de programmation Le langage machine est le langage compris par le microprocesseur. Ce langage est difficile à maîtriser puisque chaque instruction est codée par une séquence propre de bits. Afin de faciliter la tâche du programmeur, on a créé différents langages plus ou moins évolués. Le langage assembleur est le langage le plus « proche » du langage machine. Il est composé par des instructions en général assez rudimentaires que l’on appelle des mnémoniques. Ce sont essentiellement des opérations de transfert de données entre les registres et l'extérieur du microprocesseur (mémoire ou périphérique), ou des opérations arithmétiques ou logiques. Chaque instruction représente un code machine différent. Chaque microprocesseur peut posséder un assembleur différent.
La difficulté de mise en œuvre de ce type de langage, et leur forte dépendance avec la machine
a nécessité la conception de langages de haut niveau, plus adaptés à l'homme, et aux applications qu'il cherchait à développer. Faisant abstraction de toute architecture de machine, ces langages permettent l'expression d'algorithmes sous une forme plus facile à apprendre, et à dominer (C, Pascal, Java, etc…). Chaque instruction en langage de haut niveau correspondra à une succession
d’instructions en langage assembleur. Une fois développé, le programme en langage de haut niveau n’est donc pas compréhensible par le microprocesseur. Il faut le compiler pour le traduire en assembleur puis l’assembler pour le convertir en code machine compréhensible par le microprocesseur. Ces opérations sont réalisées à partir de logiciels spécialisés appelés compilateur et assembleur.
Exemple de programme :

4.5 Performances d’un microprocesseur
On peut caractériser la puissance d’un microprocesseur par le nombre d’instructions qu’il est
capable de traiter par seconde. Pour cela, on définit :
 Le CPI (Cycle Par Instruction) qui représente le nombre moyen de cycles d’horloge nécessaire pour l’exécution d’une instruction pour un microprocesseur donné. Le MIPS (Millions d'Instructions Par Seconde) qui représente la puissance de traitement du microprocesseur.
Le CPI (Cycle Par Instruction) qui représente le nombre moyen de cycles d’horloge nécessaire pour l’exécution d’une instruction pour un microprocesseur donné. Le MIPS (Millions d'Instructions Par Seconde) qui représente la puissance de traitement du microprocesseur.
Pour augmenter les performances d’un microprocesseur, on peut donc soit augmenter la fréquence
d'horloge (limitation matérielle), soit diminuer le CPI (choix d'un jeu d'instruction adapté).
4.6 Notion d’architecture RISC et CISC
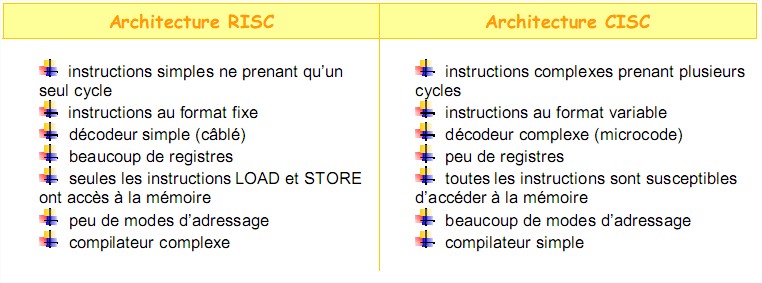
Actuellement l’architecture des microprocesseurs se composent de deux grandes familles :
L’ architecture CISC (Complex Instruction Set Computer) L’architecture RISC (Reduced Instruction Set Computer) 4.6.1 L’architecture CISC
4.6.1.1 Pourquoi
Par le passé la conception de machines CISC était la seule envisageable. En effet, vue que la
mémoire travaillait très lentement par rapport au processeur, on pensait qu’il était plus intéressant de soumettre au microprocesseur des instructions complexes. Ainsi, plutôt que de coder une opération complexe par plusieurs instructions plus petites (qui demanderaient autant d’accès mémoire très lent), il semblait préférable d’ajouter au jeu d’instructions du microprocesseur une instruction complexe qui se chargerait de réaliser cette opération. De plus, le développement des langages de haut niveau posa de nombreux problèmes quant à la conception de compilateurs. On a donc eu tendance à incorporer au niveau processeur des instructions plus proches de la structure de ces langages.
C’est donc une architecture avec un grand nombre d’instructions où le microprocesseur doit
exécuter des tâches complexes par instruction unique. Pour une tâche donnée, une machine CISC
exécute ainsi un petit nombre d’instructions mais chacune nécessite un plus grand nombre de cycles d’horloge. Le code machine de ces instructions varie d’une instruction à l’autre et nécessite donc un décodeur complexe (micro-code)
4.6.2 L’architecture RISC
4.6.2.1 Pourquoi
Des études statistiques menées au cours des années 70 ont clairement montré que les programmes générés par les compilateurs se contentaient le plus souvent d'affectations,d'additions et de multiplications par des constantes. Ainsi, 80% des traitements des langages de haut niveau faisaient appel à seulement 20% des instructions du microprocesseur. D’où l’idée de réduire le jeu d’instructions à celles le plus couramment utilisées et d’en améliorer la vitesse de traitement.
C’est donc une architecture dans laquelle les instructions sont en nombre réduit (chargement,
branchement, appel sous-programme). Les architectures RISC peuvent donc être réalisées à partir de séquenceur câblé. Leur réalisation libère de la surface permettant d’augmenter le nombres de
registres ou d’unités de traitement par exemple. Chacune de ces instructions s’exécutent ainsi en un cycle d’horloge. Bien souvent, ces instructions ne disposent que d’un seul mode d’adressage. Les accès à la mémoire s’effectue seulement à partir de deux instructions (Load et Store). Par contre, les instructions complexes doivent être réalisées à partir de séquences basées sur les instructions élémentaires, ce qui nécessite un compilateur très évolué dans le cas de programmation en langage de haut niveau.
4.6.3 Comparaison
Le choix dépendra des applications visées. En effet, si on diminue le nombre d'instructions, on crée des instructions complexes (CISC) qui nécessitent plus de cycles pour être décodées et si on diminue le nombre de cycles par instruction, on crée des instructions simples (RISC) mais on augmente alors le nombre d'instructions nécessaires pour réaliser le même traitement.
L'ensemble des améliorations des microprocesseurs visent à diminuer le temps d'exécution du
programme.
La première idée qui vient à l’esprit est d’augmenter tout simplement la fréquence de l’horloge
du microprocesseur. Mais l’accélération des fréquences provoque un surcroît de consommation ce qui entraîne une élévation de température. On est alors amené à équiper les processeurs de systèmes de refroidissement ou à diminuer la tension d’alimentation.
Une autre possibilité d’augmenter la puissance de traitement d’un microprocesseur est de diminuer le nombre moyen de cycles d’horloge nécessaire à l’exécution d’une instruction. Dans le cas d’une programmation en langage de haut niveau, cette amélioration peut se faire en optimisant le compilateur. Il faut qu’il soit capable de sélectionner les séquences d’instructions minimisant le
nombre moyen de cycles par instructions. Une autre solution est d’utiliser une architecture de microprocesseur qui réduise le nombre de cycles par instruction.
4.7.1 Architecture pipeline
4.7.1.1 Principe
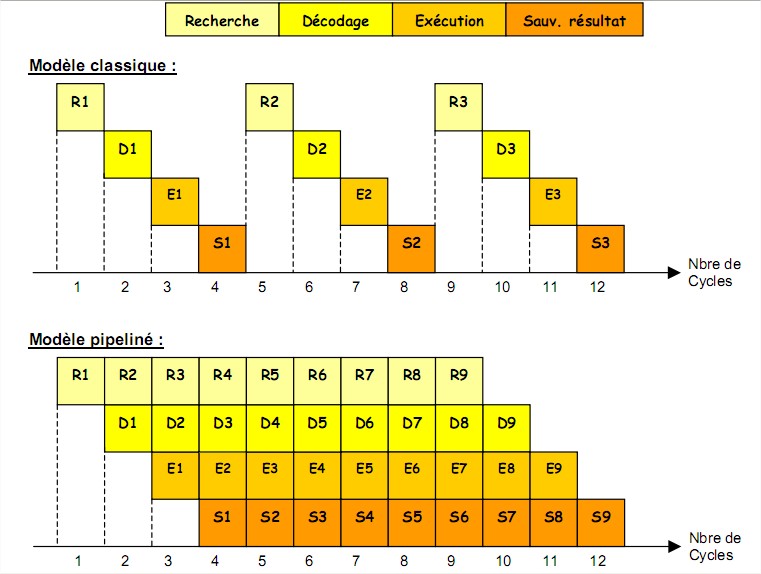
L’exécution d’une instruction est décomposée en une succession d’étapes et chaque étape correspond à l’utilisation d’une des fonctions du microprocesseur. Lorsqu’une instruction se trouve
dans l’une des étapes, les composants associés aux autres étapes ne sont pas utilisés. Le fonctionnement d’un microprocesseur simple n’est donc pas efficace.
L’architecture pipeline permet d’améliorer l’efficacité du microprocesseur. En effet, lorsque la
première étape de l’exécution d’une instruction est achevée, l’instruction entre dans la seconde étape de son exécution et la première phase de l’exécution de l’instruction suivante débute. Il peut donc y avoir une instruction en cours d’exécution dans chacune des étapes et chacun des composants du microprocesseur peut être utilisé à chaque cycle d’horloge. L’efficacité est maximale. Le temps d’exécution d’une instruction n’est pas réduit mais le débit d’exécution des instructions est considérablement augmenté. Une machine pipeline se caractérise par le nombre d’étapes utilisées pour l’exécution d’une instruction, on appelle aussi ce nombre d’étapes le nombre d’étages du pipeline.
Exemple de l’exécution en 4 phases d’une instruction :
4.7.1.2 Gain de performance
Dans cette structure, la machine débute l’exécution d’une instruction à chaque cycle et le
pipeline est pleinement occupé à partir du quatrième cycle. Le gain obtenu dépend donc du nombre
d’étages du pipeline. En effet, pour exécuter n instructions, en supposant que chaque instruction
s’exécute en k cycles d’horloge, il faut :
n.k cycles d’horloge pour une exécution séquentielle. k cycles d’horloge pour exécuter la première instruction puis n-1 cycles pour les n-1 instructions suivantes si on utilise un pipeline de k étages Le gain obtenu est donc de :

Remarques :
Le temps de traitement dans chaque unité doit être à peu près égal sinon les unités rapides doivent
attendre les unités lentes.
Exemples :
L’Athlon d’AMD comprend un pipeline de 11 étages.
Les Pentium 2, 3 et 4 d’Intel comprennent respectivement un pipeline de 12, 10 et 20 étages.
4.7.1.3 Problèmes
La mise en place d’un pipeline pose plusieurs problèmes. En fait, plus le pipeline est long, plus le nombre de cas où il n’est pas possible d’atteindre la performance maximale est élevé. Il existe 3 principaux cas où la performance d’un processeur pipeliné peut être dégradé ; ces cas de dégradations de performances sont appelés des aléas :
aléa structurel qui correspond au cas où deux instructions ont besoin d’utiliser la même ressource du processeur (conflit de dépendance), aléa de données qui intervient lorsqu’une instruction produit un résultat et que l’instruction suivante utilise ce résultat avant qu’il n’ait pu être écrit dans un registre, aléa de contrôle qui se produit chaque fois qu’une instruction de branchement est exécutée. Lorsqu’une instruction de branchement est chargée, il faut normalement attendre de connaître l’adresse de destination du branchement pour pouvoir charger l’instruction suivante. Les instructions qui suivent le saut et qui sont en train d’être traitées dans les étages inférieurs le sont en général pour rien, il faudra alors vider le pipeline. Pour atténuer l’effet des branchements, on peut spécifier après le branchement des instructions qui seront toujours exécutées. On fait aussi appel à la prédiction de branchement qui a pour but de recenser lors de branchements le comportement le plus probable. Les mécanismes de prédiction de branchement permettent d'atteindre une fiabilité de prédiction de l'ordre de 90 à 95 %.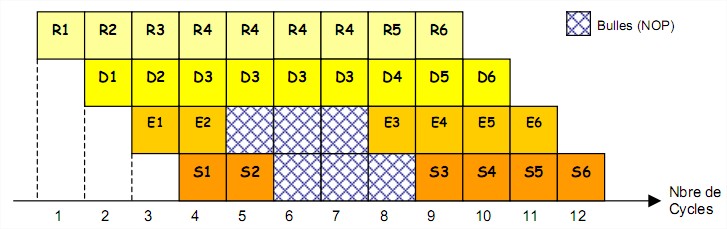
Lorsqu’un aléa se produit, cela signifie qu’une instruction ne peut continuer à progresse dans
le pipeline. Pendant un ou plusieurs cycles, l’instruction va rester bloquée dans un étage du pipeline, mais les instructions situées plus en avant pourront continuer à s’exécuter jusqu’à ce que l’aléa ait disparu. Plus le pipeline possède d’étages, plus la pénalité est grande. Les compilateurs s’efforcent d’engendrer des séquences d’instructions permettant de maximiser le remplissage du pipeline. Les étages vacants du pipeline sont appelés des « bulles » de pipeline, en pratique une bulle correspond en fait à une instruction NOP (No OPeration) émise à la place de l’instruction bloquée.
4.7.2 Notion de cache mémoire
4.7.2.1 Problème posé
L’écart de performance entre le microprocesseur et la mémoire ne cesse de s’accroître. En
effet, les composants mémoire bénéficient des mêmes progrès technologique que les
microprocesseurs mais le décodage des adresses et la lecture/écriture d’une données sont des
étapes difficiles à accélérer. Ainsi, le temps de cycle processeur décroît plus vite que le temps d’accès mémoire entraînant un goulot d’étranglement. La mémoire n'est plus en mesure de délivrer des informations aussi rapidement que le processeur est capable de les traiter. Il existe donc une latence d’accès entre ces deux organes.
4.7.2.2 Principe
Depuis le début des années 80, une des solutions utilisées pour masquer cette latence est de disposer une mémoire très rapide entre le microprocesseur et la mémoire. Elle est appelée cache
mémoire. On compense ainsi la faible vitesse relative de la mémoire en permettant au microprocesseur d’acquérir les données à sa vitesse propre. On la réalise à partir de cellule SRAM de taille réduite (à cause du coût). Sa capacité mémoire est donc très inférieure à celle de la mémoire principale et sa fonction est de stocker les informations les plus récentes ou les plus souvent utilisées par le microprocesseur. Au départ cette mémoire était intégrée en dehors du microprocesseur mais elle fait maintenant partie intégrante du microprocesseur et se décline même sur plusieurs niveaux. Le principe de cache est très simple : le microprocesseur n’a pas conscience de sa présence et lui envoie toutes ses requêtes comme s’il agissait de la mémoire principale :
Soit la donnée ou l’instruction requise est présente dans le cache et elle est alors envoyée directement au microprocesseur. On parle de succès de cache. (a) Soit la donnée ou l’instruction n’est pas dans le cache, et le contrôleur de cache envoie alors une requête à la mémoire principale. Une fois l’information récupérée, il la renvoie au microprocesseur tout en la stockant dans le cache. On parle de défaut de cache. (b) 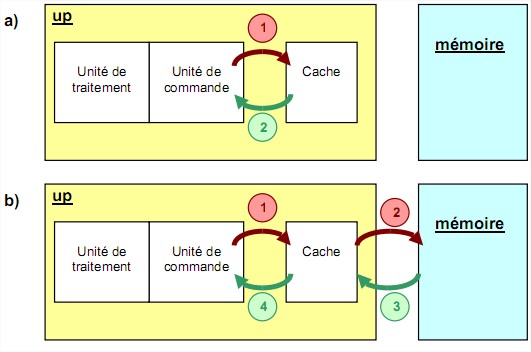
Bien entendu, le cache mémoire n’apporte un gain de performance que dans le premier cas. Sa
performance est donc entièrement liée à son taux de succès. Il est courant de rencontrer des taux de succès moyen de l’ordre de 80 à 90%.
Remarques :
 Un cache utilisera une carte pour savoir quels sont les mots de la mémoire principale dont il
Un cache utilisera une carte pour savoir quels sont les mots de la mémoire principale dont il possède une copie. Cette carte devra avoir une structure simple.
 Il existe dans le système deux copies de la même information : l’originale dans la mémoire
Il existe dans le système deux copies de la même information : l’originale dans la mémoire principale et la copie dans le cache. Si le microprocesseur modifie la donnée présente dans le cache, il faudra prévoir une mise à jour de la mémoire principale.
 Lorsque le cache doit stocker une donnée, il est amené à en effacer une autre. Il existe donc un
Lorsque le cache doit stocker une donnée, il est amené à en effacer une autre. Il existe donc un contrôleur permettant de savoir quand les données ont été utilisées pour la dernière fois. La plus
ancienne non utilisée est alors remplacée par la nouvelle.
 A noter que l’on peut reprendre le même principe pour les disques durs et CD/DVD.
A noter que l’on peut reprendre le même principe pour les disques durs et CD/DVD. 4.7.3 Architecture superscalaire
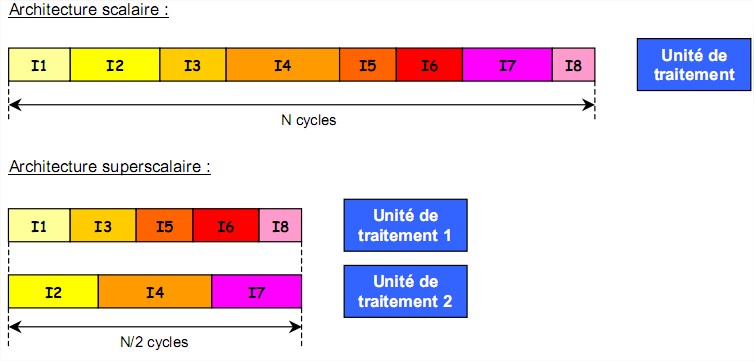
Une autre façon de gagner en performance est d’exécuter plusieurs instructions en même temps. L'approche superscalaire consiste à doter le microprocesseur de plusieurs unités de traitement
travaillant en parallèle. Les instructions sont alors réparties entre les différentes unités d'exécution. Il faut donc pouvoir soutenir un flot important d’instructions et pour cela disposer d’un cache performant.
Remarque :
C'est le type d'architecture mise en oeuvre dans les premiers Pentium d'Intel apparus en 1993.
4.7.4 Architecture pipeline et superscalaire
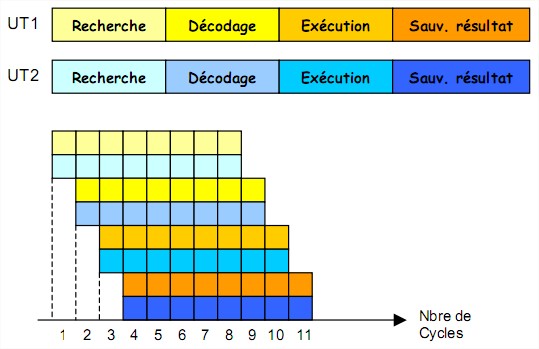
Le principe est de d’exécuter les instructions de façon pipelinée dans chacune des unités de
traitement travaillant en parallèle.
4.8.1 Le microcontrôleur
Ce sont des systèmes minimum sur une seule puce. Ils contiennent un CPU, de la RAM, de la
ROM et des ports d’Entrée/Sorties (parallèles, séries, I2C, etc..). Ils comportent aussi des fonctions spécifiques comme des compteurs programmables pour effectuer des mesures de durées, des CAN voir des CNA pour s’insérer au sein de chaînes d’acquisition, des interfaces pour réseaux de terrain, etc ...
Il est adapté pour répondre au mieux aux besoin des applications embarquées (appareil
électroménagers, chaîne d’acquisition, lecteur carte à puce, etc...). Il est par contre généralement
moins puissant en terme de rapidité, de taille de données traitables ou de taille de mémoire adressable qu’un microprocesseur.
4.8.2 Le processeur de signal
Le processeur de signal est beaucoup plus spécialisé. Alors qu'un microprocesseur n'est pas
conçu pour une application spécifique, le processeur DSP (Digital Signal Processor) est optimisé pour effectuer du traitement numérique du signal (calcul de FFT, convolution, filtrage numérique, etc...).
Les domaines d’application des D.S.P étaient à l’origine les télécommunications et le secteur
militaire. Aujourd’hui, les applications se sont diversifiées vers le multimédia (lecteur CD, MP3, etc..) l’électronique grand public (télévision numérique, téléphone portable, etc…), l’automatique,
l’instrumentation, l’électronique automobile, etc…
4.9 Exemples
Voici deux exemples d’architecture de deux processeurs qui tenaient le haut du pavé lors de leur sortie en 1999 : l’Athlon d’AMD et le Pentium III d’Intel. (f ≈500MHz)
4.9.1 AMD Athlon :
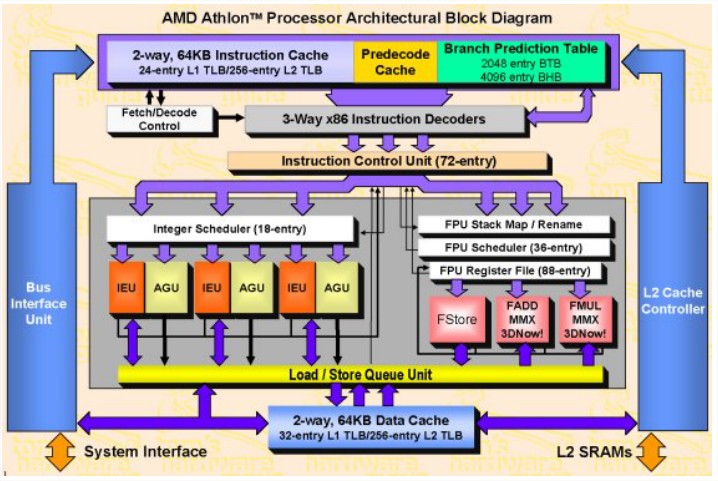
AGU : Adress Generation Unit BTB : Branch Target Buffer
IEU : Integer Execution Unit BHB : Branch History Buffer
 Caractéristiques: 9 unité de traitement se composant de :
Caractéristiques: 9 unité de traitement se composant de :  1 ALU (traitement entier) comprenant 6 unités de traitement : 3 unités pour le traitement des données (IEU) 3 unités pour l’adressage des données (AGU) 1 FPU (traitement réel) comprenant 3 unités : 1 FPU store 1 Fadd / MMX / 3Dnow ! 1 Fmul /MMX / 3Dnow ! Pipeline entier : 10 étages, pipeline flottant : 15 étages. Prédiction dynamique et exécution du traitement "dans le désordre" (out-of-order) 6 unités de décodage parallèles (3 micro-programmées, 3 câblées) mais seules 3 peuvent
1 ALU (traitement entier) comprenant 6 unités de traitement : 3 unités pour le traitement des données (IEU) 3 unités pour l’adressage des données (AGU) 1 FPU (traitement réel) comprenant 3 unités : 1 FPU store 1 Fadd / MMX / 3Dnow ! 1 Fmul /MMX / 3Dnow ! Pipeline entier : 10 étages, pipeline flottant : 15 étages. Prédiction dynamique et exécution du traitement "dans le désordre" (out-of-order) 6 unités de décodage parallèles (3 micro-programmées, 3 câblées) mais seules 3 peuvent fonctionner en même temps.
Cache mémoire de niveau 1 (L1) : 128 Ko 64 Ko pour les données 64 Ko pour les instructions 22 millions de transistors 4.9.2 Intel Pentium III
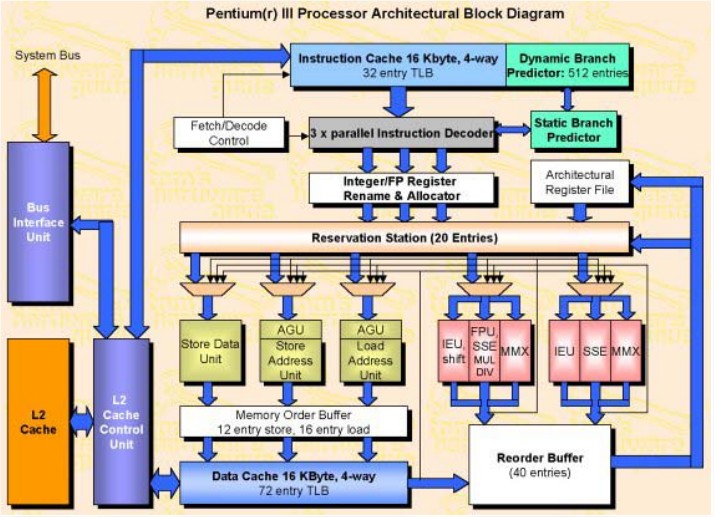
 Plusieurs unités de traitement mais au 5 instructions exécutées en même temps sur 5 ports : Port 0 : ALU, FPU, AGU MMX et SSE Port 1 : ALU, SSE, MMX Port 2 : AGU (load) Port 3 : AGU (store) Port 4 : Store Data Unit Pipeline entier : 12 à 17 étages, pipeline flottant : environ 25 étages Prédiction dynamique et exécution du traitement "dans le désordre" (out-of-order) 3 unités de décodage parallèles : 1 micro-programmée, 2 câblées. 5 pipelines de 10 étages Cache mémoire de niveau 1 (L1) : 32 Ko 16 Ko pour les données 16 Ko pour les instructions Contrôleur de cache L2 supportant jusqu’à 512 Ko à ½ de la vitesse CPU 9.5 millions de transistors
Plusieurs unités de traitement mais au 5 instructions exécutées en même temps sur 5 ports : Port 0 : ALU, FPU, AGU MMX et SSE Port 1 : ALU, SSE, MMX Port 2 : AGU (load) Port 3 : AGU (store) Port 4 : Store Data Unit Pipeline entier : 12 à 17 étages, pipeline flottant : environ 25 étages Prédiction dynamique et exécution du traitement "dans le désordre" (out-of-order) 3 unités de décodage parallèles : 1 micro-programmée, 2 câblées. 5 pipelines de 10 étages Cache mémoire de niveau 1 (L1) : 32 Ko 16 Ko pour les données 16 Ko pour les instructions Contrôleur de cache L2 supportant jusqu’à 512 Ko à ½ de la vitesse CPU 9.5 millions de transistors
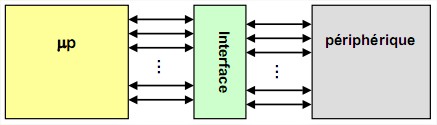
La fonction d’un système à microprocesseurs, quel qu’il soit, est le traitement de l’information. Il est donc évident qu’il doit acquérir l’information fournie par son environnement et restituer les résultats de ses traitements. Chaque système est donc équipé d’une ou plusieurs interfaces d’entrées/sorties permettant d’assurer la communication entre le microprocesseur et le monde extérieur.
Les techniques d’entrées/sorties sont très importantes pour les performances du système.
Rien ne sert d’avoir un microprocesseur calculant très rapidement s’il doit souvent perdre son temps pour lire des données ou écrire ses résultats. Durant une opération d’entrée/sortie, l’information est échangée entre la mémoire principale et un périphérique relié au système. Cet échange nécessite une interface (ou contrôleur) pour gérer la connexion. Plusieurs techniques sont employées pour effectuer ces échanges.
Les techniques d’entrées/sorties sont très importantes pour les performances du système.
Rien ne sert d’avoir un microprocesseur calculant très rapidement s’il doit souvent perdre son temps pour lire des données ou écrire ses résultats. Durant une opération d’entrée/sortie, l’information est échangée entre la mémoire principale et un périphérique relié au système. Cet échange nécessite une interface (ou contrôleur) pour gérer la connexion. Plusieurs techniques sont employées pour effectuer ces échanges.
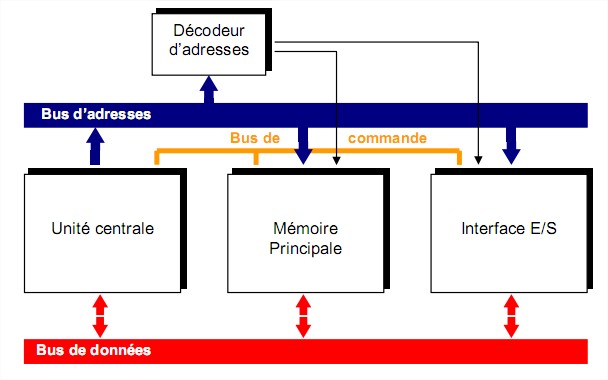
5.1 L’interface d’entrée/sortie
5.1.1 Rôle
Chaque périphérique sera relié au système par l’intermédiaire d’une interface (ou contrôleur)
dont le rôle est de :
dont le rôle est de :
 Connecter le périphérique au bus de données Gérer les échanges entre le microprocesseur et le périphérique
Connecter le périphérique au bus de données Gérer les échanges entre le microprocesseur et le périphérique
5.1.2 Constitution
Pour cela, l’interface est constituée par :
Un registre de commande dans lequel le processeur décrit le travail à effectuer (sens de transfert, mode de transfert).
Un ou plusieurs registres de données qui contiennent les mots à échanger entre le périphérique et la mémoire
Un registre d’état qui indique si l’unité d’échange est prête, si l’échange s’est bien déroulé, etc…
On accède aux données de l’interface par le biais d’un espace d’adresses d’entrées/sorties.
Pour cela, l’interface est constituée par :
Un registre de commande dans lequel le processeur décrit le travail à effectuer (sens de transfert, mode de transfert). Un ou plusieurs registres de données qui contiennent les mots à échanger entre le périphérique et la mémoire Un registre d’état qui indique si l’unité d’échange est prête, si l’échange s’est bien déroulé, etc… On accède aux données de l’interface par le biais d’un espace d’adresses d’entrées/sorties.
5.2 Techniques d’échange de données
Avant d’envoyer ou de recevoir des informations, le microprocesseur doit connaître l’état du
périphérique. En effet, le microprocesseur doit savoir si un périphérique est prêt à recevoir ou à
transmettre une information pour que la transmission se fasse correctement. Il existe 2 modes
d’échange d’information :
Avant d’envoyer ou de recevoir des informations, le microprocesseur doit connaître l’état du
périphérique. En effet, le microprocesseur doit savoir si un périphérique est prêt à recevoir ou à
transmettre une information pour que la transmission se fasse correctement. Il existe 2 modes
d’échange d’information :
Le mode programmé par scrutation ou interruption où le microprocesseur sert d’intermédiaire entre la mémoire et le périphérique Le mode en accès direct à la mémoire (DMA) où le microprocesseur ne se charge pas de l’échange de données.
5.2.1 Echange programmé
5.2.1.1 Scrutation
Dans la version la plus rudimentaire, le microprocesseur interroge l’interface pour savoir si des
transferts sont prêts. Tant que des transferts ne sont pas prêts, le microprocesseur attend.
L’inconvénient majeur est que le microprocesseur se retrouve souvent en phase d’attente. Il
est complètement occupé par l’interface d’entrée/sortie. De plus, l’initiative de l’échange de données est dépendante du programme exécuté par le microprocesseur. Il peut donc arriver que des requêtes d’échange ne soient pas traitées immédiatement car le microprocesseur ne se trouve pas encore dans la boucle de scrutation. Ce type d’échange est très lent.
5.2.1.1 Scrutation
Dans la version la plus rudimentaire, le microprocesseur interroge l’interface pour savoir si des
transferts sont prêts. Tant que des transferts ne sont pas prêts, le microprocesseur attend.
L’inconvénient majeur est que le microprocesseur se retrouve souvent en phase d’attente. Il
est complètement occupé par l’interface d’entrée/sortie. De plus, l’initiative de l’échange de données est dépendante du programme exécuté par le microprocesseur. Il peut donc arriver que des requêtes d’échange ne soient pas traitées immédiatement car le microprocesseur ne se trouve pas encore dans la boucle de scrutation. Ce type d’échange est très lent.
5.2.1.2 Interruption
Une interruption est un signal, généralement asynchrone au programme en cours, pouvant
être émis par tout dispositif externe au microprocesseur. Le microprocesseur possède une ou
plusieurs entrées réservées à cet effet. Sous réserve de certaines conditions, elle peut interrompre le travail courant du microprocesseur pour forcer l’exécution d’un programme traitant la cause de
l’interruption. Dans un échange de données par interruption, le microprocesseur exécute donc son
programme principal jusqu’à ce qu’il reçoive un signal sur sa ligne de requête d’interruption. Il se
charge alors d’effectuer le transfert de données entre l’interface et la mémoire.
Une interruption est un signal, généralement asynchrone au programme en cours, pouvant
être émis par tout dispositif externe au microprocesseur. Le microprocesseur possède une ou
plusieurs entrées réservées à cet effet. Sous réserve de certaines conditions, elle peut interrompre le travail courant du microprocesseur pour forcer l’exécution d’un programme traitant la cause de
l’interruption. Dans un échange de données par interruption, le microprocesseur exécute donc son
programme principal jusqu’à ce qu’il reçoive un signal sur sa ligne de requête d’interruption. Il se
charge alors d’effectuer le transfert de données entre l’interface et la mémoire.
Principe de fonctionnement d’une interruption :
Avant chaque exécution d’instructions, le microprocesseur examine si il y a eu une requête
sur sa ligne d’interruption. Si c’est le cas, il interrompt toutes ces activités et sauvegarde l’état présent (registres, PC, accumulateurs, registre d’état) dans un registre particulier appelé pile. Les données y sont ‘’entassées’’ comme on empile des livres (la première donnée sauvegardée sera donc la dernière à être restituée). Ensuite, il exécute le programme d’interruption puis restitue l’état sauvegardé avant de reprendre le programme principale.
Avant chaque exécution d’instructions, le microprocesseur examine si il y a eu une requête
sur sa ligne d’interruption. Si c’est le cas, il interrompt toutes ces activités et sauvegarde l’état présent (registres, PC, accumulateurs, registre d’état) dans un registre particulier appelé pile. Les données y sont ‘’entassées’’ comme on empile des livres (la première donnée sauvegardée sera donc la dernière à être restituée). Ensuite, il exécute le programme d’interruption puis restitue l’état sauvegardé avant de reprendre le programme principale.
Remarques :
 Certaine source d’interruption possède leur propre autorisation de fonctionnement sous la forme d’un bit à positionner, on l’appelle le masque d’interruption.
Certaine source d’interruption possède leur propre autorisation de fonctionnement sous la forme d’un bit à positionner, on l’appelle le masque d’interruption.  On peut donc interdire ou autoriser certaines sources d’interruptions, on les appelle les interruptions masquables.
On peut donc interdire ou autoriser certaines sources d’interruptions, on les appelle les interruptions masquables.  Chaque source d’interruption possède un vecteur d’interruption où est sauvegardé l’adresse de départ du programme à exécuter.
Chaque source d’interruption possède un vecteur d’interruption où est sauvegardé l’adresse de départ du programme à exécuter.  Les interruptions sont classées par ordre de priorité. Dans le cas où plusieurs interruptions
Les interruptions sont classées par ordre de priorité. Dans le cas où plusieurs interruptions se présentent en même temps, le microprocesseur traite d’abord celle avec la priorité la plus élevée.
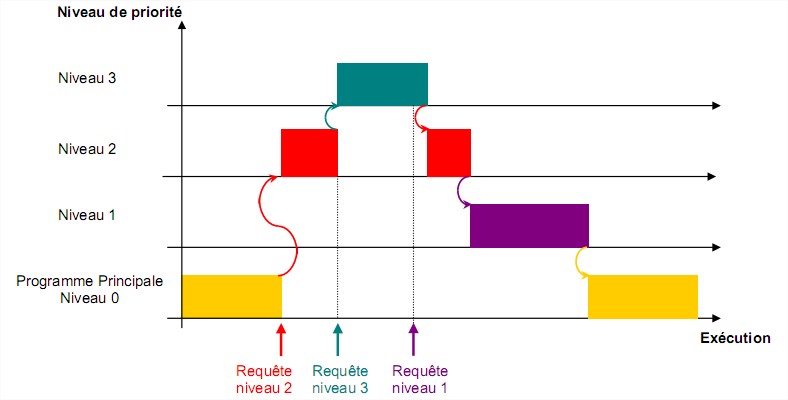
5.2.2 Echange direct avec la mémoire
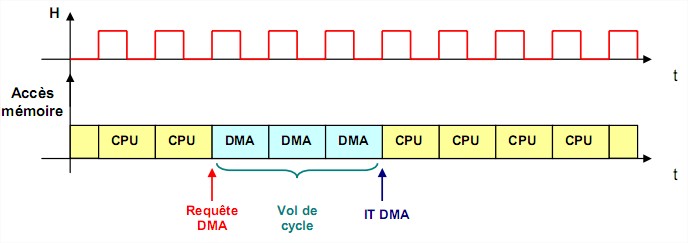
Ce mode permet le transfert de blocs de données entre la mémoire et un périphérique sans passer par le microprocesseur. Pour cela, un circuit appelé contrôleur de DMA (Direct Memory Access) prend en charge les différentes opérations.
Le DMA se charge entièrement du transfert d’un bloc de données. Le microprocesseur doit
tout de même :
Ce mode permet le transfert de blocs de données entre la mémoire et un périphérique sans passer par le microprocesseur. Pour cela, un circuit appelé contrôleur de DMA (Direct Memory Access) prend en charge les différentes opérations.
Le DMA se charge entièrement du transfert d’un bloc de données. Le microprocesseur doit
tout de même :
initialiser l’échange en donnant au DMA l’identification du périphérique concerné donner le sens du transfert fournir l’adresse du premier et du dernier mot concernés par le transfert
Un contrôleur de DMA est doté d’un registre d’adresse, d’un registre de donnée, d’un compteur et d’un dispositif de commande (logique câblée). Pour chaque mot échangée, le DMA demande au microprocesseur le contrôle du bus, effectue la lecture ou l'écriture mémoire à l'adresse contenue dans son registre et libère le bus. Il incrémente ensuite cette adresse et décrémente son compteur. Lorsque le compteur atteint zéro, le dispositif informe le processeur de la fin du transfert par
une ligne d'interruption.
Le principal avantage est que pendant toute la durée du transfert, le processeur est libre
d'effectuer un traitement quelconque. La seule contrainte est une limitation de ses propres accès
mémoire pendant toute la durée de l'opération, puisqu'il doit parfois retarder certains de ses accès
pour permettre au dispositif d'accès direct à la mémoire d'effectuer les siens : il y a apparition de vols de cycle.
une ligne d'interruption.
Le principal avantage est que pendant toute la durée du transfert, le processeur est libre
d'effectuer un traitement quelconque. La seule contrainte est une limitation de ses propres accès
mémoire pendant toute la durée de l'opération, puisqu'il doit parfois retarder certains de ses accès
pour permettre au dispositif d'accès direct à la mémoire d'effectuer les siens : il y a apparition de vols de cycle.
5.3 Types de liaisons
Les systèmes à microprocesseur utilisent deux types de liaison différentes pour se connecter à
des périphériques :
liaison parallèle
liaison série
On caractérise un type de liaison par sa vitesse de transmission ou débit (en bit/s).
Les systèmes à microprocesseur utilisent deux types de liaison différentes pour se connecter à
des périphériques :
liaison parallèle liaison série On caractérise un type de liaison par sa vitesse de transmission ou débit (en bit/s).
5.3.1 Liaison parallèle
Dans ce type de liaison, tous les bits d’un mot sont transmis simultanément. Ce type de transmission permet des transferts rapides mais reste limitée à de faibles distances de transmission à cause du nombre important de lignes nécessaires (coût et encombrement) et des problèmes d’interférence électromagnétique entre chaque ligne (fiabilité). La transmission est cadencée par une horloge
Dans ce type de liaison, tous les bits d’un mot sont transmis simultanément. Ce type de transmission permet des transferts rapides mais reste limitée à de faibles distances de transmission à cause du nombre important de lignes nécessaires (coût et encombrement) et des problèmes d’interférence électromagnétique entre chaque ligne (fiabilité). La transmission est cadencée par une horloge
Exemple :
Bus PCI, AGP dans un PC.
5.3.2 Liaison série
Dans ce type de liaison, les bits constitutifs d’un mot sont transmis les uns après les autres sur un seul fil. Les distances de transmission peuvent donc être plus beaucoup plus importantes mais la vitesse de transmission est plus faible. Sur des distance supérieures à quelques dizaines de mètres, on utilisera des modems aux extrémités de la liaison.
Bus PCI, AGP dans un PC.
5.3.2 Liaison série
Dans ce type de liaison, les bits constitutifs d’un mot sont transmis les uns après les autres sur un seul fil. Les distances de transmission peuvent donc être plus beaucoup plus importantes mais la vitesse de transmission est plus faible. Sur des distance supérieures à quelques dizaines de mètres, on utilisera des modems aux extrémités de la liaison.
La transmission de données en série peut se concevoir de deux façons différentes :
En mode synchrone, l’émetteur et le récepteur possède une horloge synchronisée qui cadence la transmission. Le flot de données peut être ininterrompu.
En mode asynchrone, la transmission s’effectue au rythme de la présence des données.
Les caractères envoyés sont encadrés par un signal start et un signal stop.
Principe de base d’une liaison série asynchrone :
Afin que les éléments communicants puissent se comprendre, il est nécessaire d’établir un protocole de transmission. Ce protocole devra être le même pour chaque élément.
En mode synchrone, l’émetteur et le récepteur possède une horloge synchronisée qui cadence la transmission. Le flot de données peut être ininterrompu. En mode asynchrone, la transmission s’effectue au rythme de la présence des données. Les caractères envoyés sont encadrés par un signal start et un signal stop.
Principe de base d’une liaison série asynchrone :
Afin que les éléments communicants puissent se comprendre, il est nécessaire d’établir un protocole de transmission. Ce protocole devra être le même pour chaque élément.
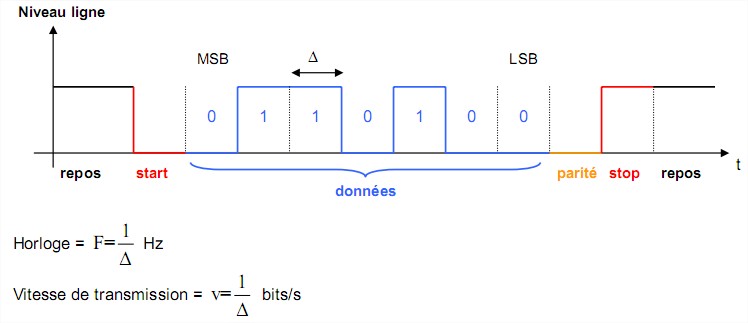
Paramètres rentrant en jeu :
 Longueur des mots transmis : 7 bits ( code ASCII ) ou 8 bits Vitesse de transmission : les vitesses varient de 110 bit/s à 128000 bit/s et détermine les fréquences d’horloge de l’émetteur et du récepteur. Parité : le mot transmis peut être suivis ou non d’un bit de parité qui sert à détecter les erreurs éventuelles de transmission. Il existe deux types de parité : paire ou impaire. Si on fixe une parité paire, le nombre total de bits à 1 transmis (bit de parité inclus) doit être paire. C’est l’inverse pour une parité impaire. bit de start : la ligne au repos est à l’état 1 (permet de tester une coupure de la ligne).
Longueur des mots transmis : 7 bits ( code ASCII ) ou 8 bits Vitesse de transmission : les vitesses varient de 110 bit/s à 128000 bit/s et détermine les fréquences d’horloge de l’émetteur et du récepteur. Parité : le mot transmis peut être suivis ou non d’un bit de parité qui sert à détecter les erreurs éventuelles de transmission. Il existe deux types de parité : paire ou impaire. Si on fixe une parité paire, le nombre total de bits à 1 transmis (bit de parité inclus) doit être paire. C’est l’inverse pour une parité impaire. bit de start : la ligne au repos est à l’état 1 (permet de tester une coupure de la ligne).
Le passage à l’état bas de la ligne va indiquer qu’un transfert va commencer. Cela permet de
synchroniser l’horloge de réception.
bit de stop : après la transmission, la ligne est positionnée à un niveau 1 pendant un certains nombre de bit afin de spécifier la fin du transfert. En principe, on transmet un, un et demi ou 2 bits de stop.
Déroulement d’une transmission :
Les paramètres du protocole de transmission doivent toujours être fixés avant la transmission.
En l’absence de transmission, la liaison est au repos au niveau haut pour détecter une éventuelle
coupure sur le support de transmission. Une transmission s’effectue de la manière suivante : L’émetteur positionne la ligne à l’état bas : c’est le bit de start.
L’émetteur positionne la ligne à l’état bas : c’est le bit de start.
synchroniser l’horloge de réception.
bit de stop : après la transmission, la ligne est positionnée à un niveau 1 pendant un certains nombre de bit afin de spécifier la fin du transfert. En principe, on transmet un, un et demi ou 2 bits de stop. Déroulement d’une transmission :
Les paramètres du protocole de transmission doivent toujours être fixés avant la transmission.
En l’absence de transmission, la liaison est au repos au niveau haut pour détecter une éventuelle
coupure sur le support de transmission. Une transmission s’effectue de la manière suivante :
L’émetteur positionne la ligne à l’état bas : c’est le bit de start.  Les bits sont transmis les un après les autres, en commençant par le bit de poids fort.
Les bits sont transmis les un après les autres, en commençant par le bit de poids fort.  Le bit de parité est éventuellement transmis.
Le bit de parité est éventuellement transmis.  L’émetteur positionne la ligne à l’état haut : c’est le bit de stop.
L’émetteur positionne la ligne à l’état haut : c’est le bit de stop. Exemple : transmission d’un mot de 7 bits (0110100)2 – Parité impaire – 1 bit de Stop
Contrôle de flux :
Le contrôle de flux permet d’envoyer des informations seulement si le récepteur est prêt ( modem ayant pris la ligne, tampon d’une imprimante vide, etc…). Il peut être réalisé de manière logiciel ou matériel.
Le contrôle de flux permet d’envoyer des informations seulement si le récepteur est prêt ( modem ayant pris la ligne, tampon d’une imprimante vide, etc…). Il peut être réalisé de manière logiciel ou matériel.
Pour contrôler le flux de données matériellement, il faudra utiliser des lignes de contrôle
supplémentaire permettant à l’émetteur et au récepteur de s’informer mutuellement de leur état
respectif (prêt ou non).
supplémentaire permettant à l’émetteur et au récepteur de s’informer mutuellement de leur état
respectif (prêt ou non).
Dans un contrôle de type logiciel, l'émetteur envoie des données et lorsque le récepteur ne
peut plus les recevoir (registre plein), il envoie une information à l’émetteur pour le prévenir, via la
liaison série. L’émetteur doit donc toujours être à l’écoute du récepteur avant d’envoyer une donnée sur la ligne.
peut plus les recevoir (registre plein), il envoie une information à l’émetteur pour le prévenir, via la
liaison série. L’émetteur doit donc toujours être à l’écoute du récepteur avant d’envoyer une donnée sur la ligne.
5.4 Notion de réseau
5.4.1 Introduction
5.4.1 Introduction
 Pour des raisons d’efficacité, on essaie de plus en plus de connecter des systèmes indépendants entre eux par l’intermédiaire d’un réseau. On permet ainsi aux utilisateurs ou aux applications de partager et d’échanger les mêmes informations.
Pour des raisons d’efficacité, on essaie de plus en plus de connecter des systèmes indépendants entre eux par l’intermédiaire d’un réseau. On permet ainsi aux utilisateurs ou aux applications de partager et d’échanger les mêmes informations. Pour faire circuler une information sur un réseau, on peut utiliser principalement deux stratégies. Soit l’information est envoyée de façon complète, soit elle décomposées en petits morceaux (paquets). Les paquets sont alors envoyés séparément sur le réseau puis réassemblés par la machine destinataire. On parle souvent de réseaux à commutations de paquets… La première stratégie n’est que très rarement utilisés en informatique car les risques d’erreurs sont trop importants. Les règles et les moyens mis en œuvre dans l’interconnexion et le dialogue des machines définissent le protocole et l’architecture du réseau. Toutes ces règles sont définies par des normes pour que des machines d’architecture différente puissent communiquer entre elles. Par exemple, pour l’envoie d’un fichier entre deux ordinateurs reliés par un réseau, il faut résoudre plusieurs problèmes :
Avant l’envoi des premiers octets du fichier, la machine source doit :
1) Accéder au réseau,
2) S’assurer qu’elle peut atteindre la machine destination en donnant une adresse,
3) S’assurer que la machine destination est prête à recevoir des données,
4) Contacter la bonne application sur la machine destination,
5) S'assurer que l’application est prête à accepter le fichier et à le stocker dans son système
de fichier
Pendant l’envoi, les 2 machines doivent :
6) Envoyer les données dans un format compris par les 2 machines,
7) Gérer l’envoi des commandes et des données et le rangement des données sur disque,
8) S’assurer que les commandes et les données sont échangées correctement et que l ’application destinataire reçoit toutes les données sans erreur et dans le bon ordre.
Au début des années 70, chaque constructeur a développé sa propre solution réseau autour
d’architecture et de protocoles privés. Mais ils se sont vite rendu compte qu’il serait impossible
d’interconnecter ces différents réseaux… Ils ont donc décidé de définir une norme commune. Ce
modèle s'appelle OSI (Open System Interconnection) et comporte 7 couches qui ont toutes une
fonctionnalité particulière. Il a été proposé par l'ISO, et il est aujourd'hui universellement adopté et
utilisé.
2) S’assurer qu’elle peut atteindre la machine destination en donnant une adresse,
3) S’assurer que la machine destination est prête à recevoir des données,
4) Contacter la bonne application sur la machine destination,
5) S'assurer que l’application est prête à accepter le fichier et à le stocker dans son système
de fichier
Pendant l’envoi, les 2 machines doivent :
6) Envoyer les données dans un format compris par les 2 machines,
7) Gérer l’envoi des commandes et des données et le rangement des données sur disque,
8) S’assurer que les commandes et les données sont échangées correctement et que l ’application destinataire reçoit toutes les données sans erreur et dans le bon ordre.
Au début des années 70, chaque constructeur a développé sa propre solution réseau autour
d’architecture et de protocoles privés. Mais ils se sont vite rendu compte qu’il serait impossible
d’interconnecter ces différents réseaux… Ils ont donc décidé de définir une norme commune. Ce
modèle s'appelle OSI (Open System Interconnection) et comporte 7 couches qui ont toutes une
fonctionnalité particulière. Il a été proposé par l'ISO, et il est aujourd'hui universellement adopté et
utilisé.
5.4.2 Le modèle OSI
Le modèle OSI définit un modèle d’architecture décomposé en couche dont la numérotation
commence par le bas. Il donne une description globale de la fonction de chaque couche. Chacune
des couches de ce modèle représente une catégorie de problème que l’on peut rencontrer dans la
conception d’un réseau. Ainsi, la mise en place d’un réseau revient à trouver une solution technologique pour chacune des couches composants le réseau. L’utilisation de couches permet
également de changer une solution technique pour une seule couche sans pour autant être obligé de
repenser toute l’architecture du réseau. De plus, chaque couche garantit à la couche supérieure
qu’elle a réalisé son travail sans erreur.
commence par le bas. Il donne une description globale de la fonction de chaque couche. Chacune
des couches de ce modèle représente une catégorie de problème que l’on peut rencontrer dans la
conception d’un réseau. Ainsi, la mise en place d’un réseau revient à trouver une solution technologique pour chacune des couches composants le réseau. L’utilisation de couches permet
également de changer une solution technique pour une seule couche sans pour autant être obligé de
repenser toute l’architecture du réseau. De plus, chaque couche garantit à la couche supérieure
qu’elle a réalisé son travail sans erreur.
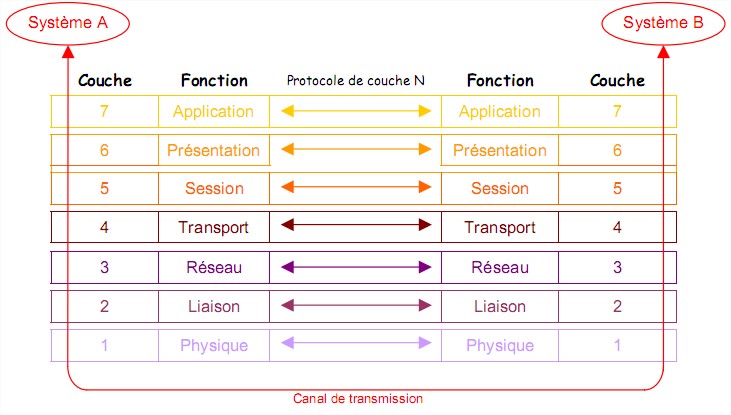
Chaque couche est identifiée par son niveau N et réalise un sous-ensemble de fonctions nécessaire à la communication avec un autre système. Pour réaliser ces fonctions de communication, la couche N s ’appuie uniquement sur la couche immédiatement inférieure par l ’intermédiaire d’une interface. Le dialogue entre les deux systèmes s’établie forcément entre deux couches de niveau
N identique mais l’échange ‘’physique’’ de données s’effectue uniquement entre les couches de niveau
1. Les règles et conventions utilisées pour ce dialogue sont appelées protocole de couche N.
On appelle les couches 1, 2, 3 et 4 les couches ‘’basses’’ et les couches 5, 6 et 7 les couches
‘’hautes’’. Les couches ‘’basses’’ sont concernées par la réalisation d’une communication fiable de
bout en bout alors que les couches ‘’hautes’’ offrent des services orientées vers les utilisateurs.
1. Les règles et conventions utilisées pour ce dialogue sont appelées protocole de couche N.
On appelle les couches 1, 2, 3 et 4 les couches ‘’basses’’ et les couches 5, 6 et 7 les couches
‘’hautes’’. Les couches ‘’basses’’ sont concernées par la réalisation d’une communication fiable de
bout en bout alors que les couches ‘’hautes’’ offrent des services orientées vers les utilisateurs.
Couche 1 : Physique La couche physique se préoccupe de résoudre les problèmes matériels. Elle normalise les
moyens mécaniques (nature et caractéristique du support : câble, voie hertzienne, fibre optique,
etc…), électrique (transmission en bande de base, modulation, puissance, etc…) et fonctionnels
(transmission synchrone/asynchrone, simplex, half/full duplex, etc..) nécessaires à l’activation, au
maintient et la désactivation des connexions physiques destinées à la transmission de bits entre deux entités de liaison de données.
Couche 2 : Liaison La couche liaison de données détecte et corrige si possible les erreurs dues au support physique
et signal à la couche réseau les erreurs irrécupérable. Elle supervise le fonctionnement de la
transmission et définit la structure syntaxique des messages, la manière d’enchaîner les échanges
selon un protocole normalisée ou non.
Cette couche reçoit les données brutes de la couche physique, les organise en trames, gère les
erreurs, retransmet les trames erronées, gère les acquittements qui indiquent si les données ont bien été transmises puis transmet les données formatées à la couche réseau supérieure.
Couche 3 : Réseau La couche réseau est chargée de l’acheminement des informations vers le destinataire. Elle gère
l’adressage, le routage, le contrôle de flux et la correction d’erreurs non réglées par la couche 2. A ce niveau là, il s’agit de faire transiter une information complète (ex : un fichier) d’une machine à une autre à travers un réseau de plusieurs ordinateurs. Elle permet donc de transmettre les trames reçues de la couche 2 en trouvant un chemin vers le destinataire.
La couche 4 : Transport Elle remplit le rôle de charnière entre les couches basses du modèle OSI et le monde des
traitements supportés par les couches 5,6 et 7. Elle assure un transport de bout en bout entre les
deux systèmes en assurant la segmentation des messages en paquets et en délivrant les informations dans l’ordre sans perte ni duplication. Elle doit acheminer les données du système source au système destination quelle que soit la topologie du réseau de communication entre les deux systèmes. Elle permet ainsi aux deux systèmes de dialoguer directement comme si le réseau n’existait pas. Elle remplit éventuellement le rôle de correction d’erreurs. Les critères de réalisation de la couche transport peuvent être le délai d’établissement de la connexion, sa probabilité d’échec, le débit souhaité, le temps de traversé, etc…
La couche 5 : Session Elle gère le dialogue entre 2 applications distantes (dialogue unidirectionnel/bidirectionnel, gestion
du tour de parole, synchronisation, etc...).
La couche 6 : Présentation Cette couche s'occupe de la partie syntaxique et sémantique de la transmission de l'information
afin d’affranchir la couche supérieure des contraintes syntaxiques. Elle effectue ainsi le codage des
caractères pour permettre à deux systèmes hétérogènes de communiquer. C’est à ce niveau que
peuvent être implantées des techniques de compression et de chiffrement de données.
La couche 7 : Application Elle gère les programmes utilisateurs et définit des standards pour les différents logiciels
commercialisés adoptent les mêmes principes (fichier virtuel, messagerie, base de données, etc…).
5.4.3 Classification des réseaux
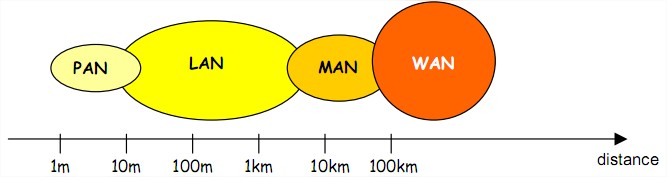
On peut établir une classification des réseaux à l’aide de leur taille. Les réseaux sont divisés en
quatre grandes familles : les PAN, LAN, MAN et WAN.
PAN : Personal Area Network ou réseau personnel Ce type de réseau interconnecte des équipements personnels comme un ordinateur portable,
un ordinateur fixe, une imprimante, etc… Il s’étend sur quelques dizaine de mètres. Les débits sont
importants (qq Mb/s).
LAN : Local Area Network ou réseau local. Ce type de réseau couvre une région géographique limitée (réseau intra-entreprise) et peut
s’étendre sur plusieurs kilomètres. Les machines adjacentes sont directement et physiquement reliées entre elles. Les débits sont très importants (de qq Mb/s à qq Gb/s).
MAN : Metropolitan Area Network ou réseau métropolitain. Ce type de réseau possède une couverture qui peut s'étendre sur toute une ville et relie des
composants appartenant à des organisations proches géographiquement( qq dizaines de kilomètres).
Ils permettent ainsi la connexion de plusieurs LAN. Le débit courant varie jusqu’à 100 Mb/s.
WAN : Wide Area Network ou étendu. Ce type de réseau couvre une très vaste région géographique et permet de relier des systèmes
dispersés à l’échelle planétaire (plusieurs milliers de km). Toutefois, étant donné la distance à
parcourir, le débit est plus faible (de 50 b/s à qq Mb/s).
5.4.4 Topologie des réseaux
La topologie physique d’un réseau définie l’architecture du réseau. Elle peut être différente
suivant le mode de transmission des informations.
En mode de diffusion, chaque système partage le même support de transmission. Toute
information envoyée par un système sur le réseau est reçue par tous les autres. A la réception,
chaque système compare son adresse avec celle transmise dans le message pour savoir si il lui est
destiné ou non. Il ne peut donc y avoir qu’un seul émetteur en même temps. Avec une telle
architecture, la rupture du support provoque l’arrêt du réseau alors que la panne d’un des éléments ne provoque pas de panne globale du réseau.
Dans le mode point à point, le support physique relie les systèmes deux à deux seulement.
Lorsque deux éléments non directement connectés entre eux veulent communiquer, ils doivent le faire par l’intermédiaire d’autres éléments. Les protocoles de routage sont alors très importants.
La topologie physique d’un réseau définie l’architecture du réseau. Elle peut être différente
suivant le mode de transmission des informations.
En mode de diffusion, chaque système partage le même support de transmission. Toute
information envoyée par un système sur le réseau est reçue par tous les autres. A la réception,
chaque système compare son adresse avec celle transmise dans le message pour savoir si il lui est
destiné ou non. Il ne peut donc y avoir qu’un seul émetteur en même temps. Avec une telle
architecture, la rupture du support provoque l’arrêt du réseau alors que la panne d’un des éléments ne provoque pas de panne globale du réseau.
Dans le mode point à point, le support physique relie les systèmes deux à deux seulement.
Lorsque deux éléments non directement connectés entre eux veulent communiquer, ils doivent le faire par l’intermédiaire d’autres éléments. Les protocoles de routage sont alors très importants.
Topologie en bus
 Facile à mettre en œuvre.
Facile à mettre en œuvre.
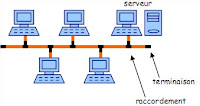 A tout moment un seule station a le droit d'envoyer un message.
A tout moment un seule station a le droit d'envoyer un message.
La rupture de la ligne provoque l'arrêt du réseau.
La panne d'une station ne provoque pas de panne du réseau.
mode de diffusion.
Facile à mettre en œuvre.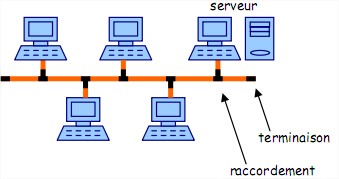 A tout moment un seule station a le droit d'envoyer un message. La rupture de la ligne provoque l'arrêt du réseau. La panne d'une station ne provoque pas de panne du réseau. mode de diffusion.
A tout moment un seule station a le droit d'envoyer un message. La rupture de la ligne provoque l'arrêt du réseau. La panne d'une station ne provoque pas de panne du réseau. mode de diffusion.  Le nœud central reçoit et renvoie tous les messages. Fonctionnement simple. Moins vulnérable sur rupture de ligne. La panne du nœud central paralyse tout le réseau. Mode point à point (avec switch) ou diffusion (avec hub).
Le nœud central reçoit et renvoie tous les messages. Fonctionnement simple. Moins vulnérable sur rupture de ligne. La panne du nœud central paralyse tout le réseau. Mode point à point (avec switch) ou diffusion (avec hub).
 Chaque station a tour à tour la possibilité de prendre la parole. Chaque station reçoit le message de son voisin en amont et le réexpédie à son voisin en aval. La station émettrice retire le message lorsqu'il lui revient. Si une station tombe en panne, il y a mise en place d’un système de contournement de la station. Si il y a rupture de ligne apparaît, tout s'arrête (sauf si on a prévu une 2ième boucle). mode point à point.
Chaque station a tour à tour la possibilité de prendre la parole. Chaque station reçoit le message de son voisin en amont et le réexpédie à son voisin en aval. La station émettrice retire le message lorsqu'il lui revient. Si une station tombe en panne, il y a mise en place d’un système de contournement de la station. Si il y a rupture de ligne apparaît, tout s'arrête (sauf si on a prévu une 2ième boucle). mode point à point. Topologie en arbre
Topologie en arbre Peut être considéré comme une topologie en étoile dans la quelle chaque station peut être une station centrale d’un sous ensemble de stations formant une structure en étoile. Complexe Mode point à point.
Peut être considéré comme une topologie en étoile dans la quelle chaque station peut être une station centrale d’un sous ensemble de stations formant une structure en étoile. Complexe Mode point à point.  Topologie en réseau maillé
Topologie en réseau maillé Tous les ordinateurs du réseau sont reliés les uns aux autres par des câbles séparés. On a une meilleure fiabilité. Si une station tombe en panne, le réseau continue de fonctionner. Si il y a rupture de ligne apparaît, le réseau continue de fonctionner. Il est très coûteux. Il est possible de diminuer les coûts en utilisant un maillage partielle (irrégulier). Mode point à point.
Tous les ordinateurs du réseau sont reliés les uns aux autres par des câbles séparés. On a une meilleure fiabilité. Si une station tombe en panne, le réseau continue de fonctionner. Si il y a rupture de ligne apparaît, le réseau continue de fonctionner. Il est très coûteux. Il est possible de diminuer les coûts en utilisant un maillage partielle (irrégulier). Mode point à point.Remarques :
Il existe deux modes de fonctionnement pour un réseau, quelque soit son architecture :
 Avec connexion : l’émetteur demande un connexion au récepteur avant d’envoyer son message. La connexion s’effectue si et seulement si ce dernier accepte, c’est le principe du téléphone. Sans connexion : l’émetteur envoie le message sur le réseau en spécifiant l’adresse du destinataire. La transmission s’effectue sans savoir si le destinataire est présent ou non, c’est le principe du courrier.
Avec connexion : l’émetteur demande un connexion au récepteur avant d’envoyer son message. La connexion s’effectue si et seulement si ce dernier accepte, c’est le principe du téléphone. Sans connexion : l’émetteur envoie le message sur le réseau en spécifiant l’adresse du destinataire. La transmission s’effectue sans savoir si le destinataire est présent ou non, c’est le principe du courrier.
Aucun commentaire:
Enregistrer un commentaire